Plik Sitemap.xml i błędy w nim – Analiza Labrika
Plik Sitemap.xml to w zasadzie mapa Twojej witryny zaprojektowana specjalnie w celu ułatwienia nawigacji i indeksowania Twojej strony przez wyszukiwarki. Znajduje się on w folderze public_html (lub katalogu głównym witryny) i zawiera ważne instrukcje dla crawlerów wyszukiwarek, które określają, które strony powinny być odwiedzane, w jakiej kolejności oraz jak często je odwiedzać.
To drastycznie przyspiesza proces indeksowania ważnych stron i pozwala crawlerom wyszukiwarek alokować ich czas indeksowania na strony o wysokiej ważności zarówno dla Ciebie, jak i dla Twoich użytkowników.
Tworzenie pliku sitemap.xml nie jest zawsze potrzebne, ale zawsze zalecane, zwłaszcza dla dużych witryn z tysiącami stron. Wraz z większymi witrynami pojawia się potrzeba, aby naprawdę upewnić się, że crawlery wyszukiwarek spędzają swój czas na tych stronach o wysokiej wartości z głęboką treścią i intencją komercyjną, a nie na pobocznych stronach oferujących cienką wartość.
Zasadniczo, gdy oprogramowanie i CMS-y automatycznie generują plik sitemap.xml, one obejmują wszystkie dostępne strony do indeksowania. Typowy właściciel witryny prawdopodobnie nie jest tego świadomy, a chociaż mogą oni ustawić noindex dla niektórych stron, ich automatycznie generowane sitemapy prawdopodobnie obejmują te strony i marnują cenny budżet indeksowania!
Zdecydowanie zaleca się używanie wtyczek, niestandardowego oprogramowania lub generatorów sitemap, aby skonfigurować konkretne URL-e do pokazania w Twojej sitemap, pewne URL-e do uniknięcia, w jakiej kolejności indeksować URL-e oraz jak często je indeksować.
Błędy w sitemap znalezione przez Labrika
Uwaga! Raport błędów sitemap będzie dostępny tylko wtedy, gdy skonfigurowane są odpowiednie uprawnienia do skanowania całej witryny. W przeciwnym razie Labrika będzie w stanie zobaczyć tylko strony specjalnie wymienione w pliku sitemap.xml, zamiast móc zobaczyć wszystkie strony na witrynie, a następnie porównać je krzyżowo ze stronami wymienionymi w sitemap.
Analiza sitemap Labrika pomaga znaleźć następujące typy błędów:
-
Strony, które istnieją w sitemap, ale nie są dostępne do indeksowania.
-
Strony, które istnieją w sitemap ale mają tag noindex.
-
Strony, które nie istnieją w sitemap, ale są indeksowalne.
Proszę zauważyć: różne wyszukiwarki przetwarzają reguły sitemap w różny sposób. Google, najczęściej, będzie indeksować tylko strony, które można osiągnąć poprzez automatyczne indeksowanie bez sitemap. To znaczy, strony, które można osiągnąć za pośrednictwem linków wewnętrznych w wyznaczonym czasie indeksowania i głębokości indeksowania dla Twojej witryny w danym dniu. Nie będą one patrzeć na Twój plik sitemap.xml, aby ustalić, które linki indeksować, ale zamiast tego używać sitemap jako przewodnika, jak często indeksować strony wymienione w sitemap.
Strona istnieje w sitemap, ale nie jest dostępna do indeksowania
Ten raport podkreśla głównie strony sierotki, które są w zasadzie stronami istniejącymi na Twojej witrynie, ale nie mającymi linków przychodzących wskazujących na nie i będącymi 'bez właściciela'.
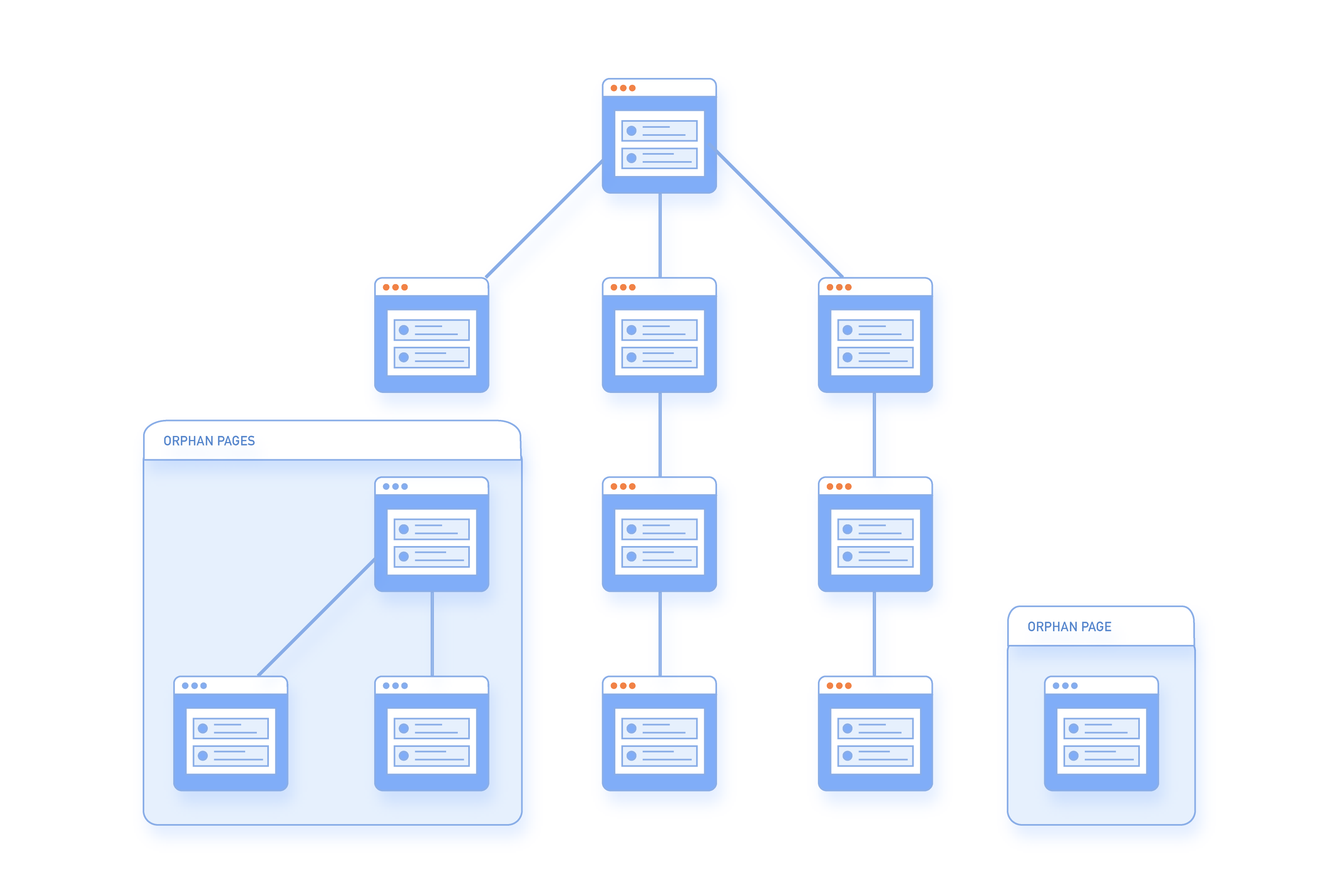
W przypadku, gdy takie strony jakimś sposobem zostaną zindeksowane przez wyszukiwarki, prawdopodobnie będą miały zero PageRank i nie będą dobrze rankować. Jest to dobrze udokumentowane online, że Google i inne duże wyszukiwarki używają wyników PageRank (i jego różnych form) do określenia mocy SEO i wartości stron. To było zaledwie kilka lat temu, gdy Google umożliwił Ci korzystanie z paska narzędziowego, który pokazywał PageRank Twoich stron, ale niestety, to zostało usunięte z sfery publicznej. Naturalnie jednak, chcesz dobry PageRank dla swoich różnych stron, więc jeśli jedna z Twoich stron lądowych kończy w tej kategorii błędów (tj. Twoja strona nie jest tylko stroną sierotką), to będziesz chciał natychmiast dotrzeć do źródła problemu.
Powszechne powody, dla których Twoja strona istnieje w sitemap, ale nie jest dostępna do indeksowania:
-
Link z oznaczonych tagiem noindex stron prowadzi do tej strony, lub strony prowadzące do tej strony nie są responsywne. W rezultacie crawler wyszukiwarki nie może poruszać się do przodu lub do tyłu, i dlatego kończy sesję.
-
Linki do potrzebnych stron są zablokowane. Na przykład, poprzez atrybut rel="nofollow". To znaczy, crawler widzi link do strony, ale nie może do niej nawigować, ponieważ jest zabroniony.
-
Nie ma linków do tej strony i jest ona naprawdę 'sierotką'.
-
Strona została usunięta w edytorze witryny/CMS, ale plik HTML nadal pozostaje aktywny na witrynie.
-
Strona istnieje w sitemap, ale nie jest indeksowalna, więc nie może być zindeksowana.
Ten rodzaj błędu jest najlepiej naprawiany poprzez wykonanie następujących czynności;
Sprawdź, które strony mają tagi noindex i nofollow i napraw je i/lub upewnij się, że strona jest poprawnie dodana do głównego menu, aby umożliwić poprawne indeksowanie. Ponadto, częściej niż rzadziej, widzimy ten rodzaj błędu na stronach komercyjnych i informacyjnych, które blokują paginację.
Jak naprawić problem?
Gdy strona jest dostępna w sitemap, ale nie ma linków wewnętrznych z żadnej innej strony na witrynie, jest znana jako strona sierotka.
Strony sierotki są złe dla SEO, ponieważ nie niosą wagi linków i dlatego są uważane za nieważne przez wyszukiwarki. Były one również wcześniej używane w black hat SEO.
Po zidentyfikowaniu ich w naszym panelu możesz:
- Przeintegrować stronę z schematem linkowania Twojej witryny, jeśli strona jest użyteczna, rankuje dla słów kluczowych lub ma backlinki z zewnętrznych witryn.
- Połączyć stronę z inną, jeśli ma prawie duplikat strony już połączonej na witrynie.
- Usunąć stronę całkowicie, jeśli nie ma użyteczności. Lub zwrócić kod 404 lub 410 (wygaśnięta treść).
- Dla stron produktowych, gdzie przedmiot może wygasł, możesz połączyć z nowymi produktami w tej samej kategorii, czyniąc stronę nowym źródłem leadów. (To jest to, co robi eBay z wygasłymi aukcjami). Pomagając generować więcej ruchu.
Strona istnieje w sitemap, ale ma tag noindex
Są to strony, które zostały zabronione do indeksowania za pomocą tagu noindex, ale nadal istnieją gdzieś w sitemap.
Ludzie oznaczają strony noindex z różnych powodów, ale posiadanie stron noindex wymienionych w sitemap może prowadzić do wycieku poufnych danych, ale najprawdopodobniej powoduje marnowanie czasu crawlerów i budżetu indeksowania.
Aby naprawić ten problem, wystarczy po prostu usunąć stronę/strony noindex z sitemap, aby uniknąć przypadkowego indeksowania strony przez wyszukiwarki, której nie powinny (chociaż normalnie przestrzegają tagu noindex).
Jak naprawić problem?
To zazwyczaj występuje, gdy strona została zablokowana do indeksowania poprzez atrybut rel="nofollow".
Włączenie tych stron do sitemap nie jest użyteczne, ponieważ zużywa budżet indeksowania i może potencjalnie prowadzić do wycieku poufnych informacji. Aby to naprawić, możesz po prostu usunąć stronę z Twojej sitemap.
Pobierz bezbłędny plik sitemap.xml od Labrika
Dla każdego z różnych raportów błędów sitemap wymienionych powyżej, Labrika oferuje Ci możliwość pobrania bezbłędnej i poprawionej wersji Twojego pliku sitemap.xml. To powinno zaoszczędzić Ci czas na ręcznej korekcie Twojego pliku sitemap.xml i najważniejsze, lepiej wykorzystać Twój budżet indeksowania wyszukiwarek.
