Duplikowany Content w SEO: Przyczyny, Wpływ i Rozwiązania
Co to jest duplikowany content?
Duplikowany content odnosi się do sytuacji, gdy wiele stron ma identyczną zawartość dostępną pod różnymi adresami URL na Twojej stronie.
To duży błąd w SEO.
Jak duplikowany content wpływa na rankingi?
Duplikowane strony szkodzą rankingowi Twojej strony z wielu powodów:
- Wyszukiwarki są wrażliwe na oryginalność treści zawartych w zasobach internetowych. Jeśli istnieje wiele stron z duplikowaną treścią, to prawdopodobnie wspomniane strony zostaną ukarane przez Google i negatywnie wpłyną na ogólny ranking Twojej strony w SERP-ach.
- Obecność dużej liczby duplikowanych stron dramatycznie komplikuje proces indeksowania strony, ponieważ wyszukiwarki muszą poświęcić swój budżet na crawlanie duplikowanych stron, zamiast Twoich stron o wysokim rankingu.
- Utrudnia to skuteczne rankingowanie stron docelowych, ponieważ wyszukiwarka nie może obiektywnie wybrać odpowiedniej strony do rankingu, ponieważ istnieje wiele instancji tej samej strony.
- "PageRank" i "waga" stron są rozcieńczone, ponieważ wewnętrzne linki są rozłożone między duplikowane strony.
- Niezrówni konkurenci mogą również znaleźć duplikowane strony na Twojej stronie i dodać do nich zewnętrzne linki. To doda je do indeksu wyszukiwarki, a w rezultacie wyszukiwarki obniżą Twoją stronę w wynikach wyszukiwania, ponieważ prawdopodobnie otrzymasz karę za duplikowany content.
- Google szczegółowo opisuje negatywny wpływ duplikowanych stron i jak najlepiej sobie z nimi poradzić w artykule zatytułowanym "Konsolidacja duplikatów URL."
Najczęstsze przyczyny duplikowanych stron to:
-
Brak przekierowania 301 dla stron z www i bez www. W tym przypadku każda strona strony jest duplikatem, ponieważ jest dostępna pod dwoma adresami.
Na przykład:
http://example.com/pagehttp://example.com/page
-
Strony strony są dostępne pod adresem z ukośnikiem i bez niego. Jeśli nie ma ustawionego przekierowania 301, oprogramowanie strony postrzega następujące strony jako różne, chociaż treść jest identyczna:
Na przykład:
- Ten URL wygląda jak folder na stronie - kończy się '/'.
http://example.com/page/ - A ten URL jest jak strona - nazwy stron mogą nie kończyć się ".php", ".html" itp.
http://example.com/page
- Ten URL wygląda jak folder na stronie - kończy się '/'.
-
Ponadto strony mogą mieć .php dodane na końcu URL. To powoduje duplikowane strony:
Na przykład:
http://example.com/page1http://example.com/page1.php
-
Strony grup produktów z różnymi opcjami filtrowania dodanymi do URL.
Na przykład:
http://example.com/cataloghttp://example.com/catalog?sort=datehttp://example.com/catalog?sort=name
-
Ten sam produkt może być obecny w różnych rozmiarach i/lub konfiguracjach produktów. Treść będzie taka sama na tych stronach, chociaż będzie wiele URL.
Na przykład:
http://example.com/catalog/shirt155http://example.com/catalog/shirt155?color=Orange
-
Paginacja stron kategorii e-commerce. URL z numerem pierwszej strony dodanym do niego jest przetwarzany dokładnie tak samo, jakby system nie przeszedł parametru z numerem w ogóle. W ten sposób okazuje się, że ta sama strona ma różne URL.
Na przykład:
http://example.com/cataloghttp://example.com/catalog?page=1
-
Możesz mieć skonfigurowany CMS, aby ignorować i nadal obsługiwać strony z dodatkowymi parametrami dodanymi. To nie jest zalecane. Jeśli strona nie pokazuje błędu 404, gdy dodasz nieistniejące parametry do strony, wspomniane strony mogą być indeksowane i są duplikatem.
Na przykład:
- Normalny URL
http://example.com/blog - Losowy dodany parametr do URL
http://example.com/blog?blablabla=7777
- Normalny URL
Jak znaleźć duplikowane strony na swojej stronie?
Możesz znaleźć duplikowane strony na swojej stronie w sekcji "Audyt SEO" -> "Duplikowane strony na Twojej stronie" w panelu Labrika.
Raport Labrika "Duplikowane strony na Twojej stronie":
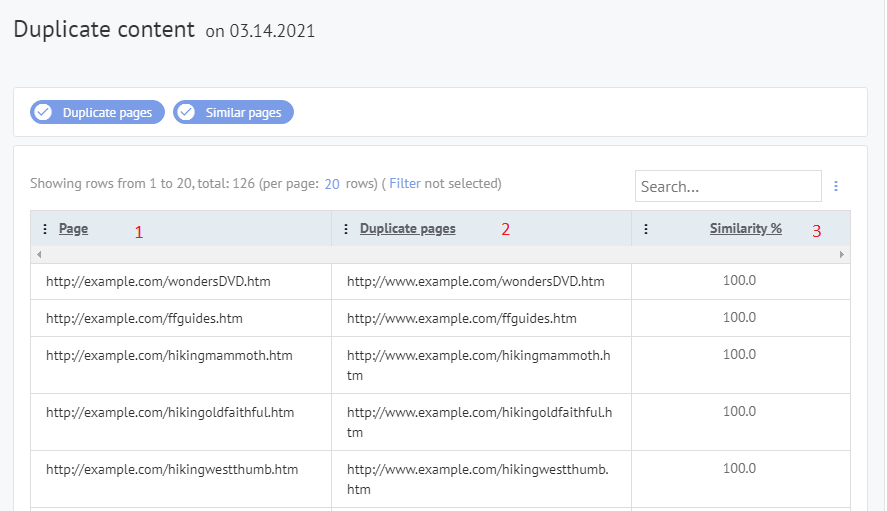
- URL strony, która ma duplikat.
- Lista duplikatów tej strony.
- Procent podobieństwa strony.
Jak wyeliminować duplikowane strony ze swojej strony?
Sposoby pozbycia się duplikatów:
-
Możesz wyeliminować niektóre błędy duplikowanych stron, po prostu usuwając niepotrzebne parametry z dozwolonych w edytorze strony. W poniższym przykładzie możesz wyraźnie zobaczyć link, który trzeba oczyścić, a drugą opcję użyć zamiast:
http://example.com/catalog/shirt155?size=XLPreferowana opcja:
http://example.com/catalog/shirt155 -
Jeśli w naszym raporcie znaleziono tylko niewielką liczbę duplikowanych stron, możesz po prostu zabronić indeksowania niektórych duplikowanych URL. Na przykład, prawdopodobnie zablokowałbyś crawlerom dostęp do folderu katalogu, który jest częścią URL do pierwszej strony poniżej, tak aby tylko drugi URL był indeksowany przez Google:
http://example.com/category/producthttp://example.com/product
Dodałbyś następujący wiersz kodu, aby zablokować indeksowanie pierwszej strony w pliku robots.txt:
# blokuj indeksowanie duplikatów stron znajdujących się w folderze '/category': Disallow: /category
-
Jeśli duplikowane strony wydają się być systemowym problemem dla całej Twojej strony, atrybut
rel=canonicaljest najlepszym rozwiązaniem.rel=canonicalto tag stosowany na stronach, który zasadniczo mówi crawlerom wyszukiwarki; "Jestem główną kopią tej strony" podczas crawlania Twojej strony.Kanoniczna strona to strona, którą rekomendujesz do indeksacji w wyszukiwarkach przez Ciebie i niesie wagę bycia 'tą' autorytatywną stroną dla konkretnego tekstu tej strony na Twojej stronie.
Powinieneś ustawić najbardziej autorytatywną stronę na liście duplikowanych stron jako stronę kanoniczną, co poinstruuje wyszukiwarki, aby ignorowały wszystkie duplikaty kanonicznej.
Atrybut jest napisany w następujący sposób:
# wiersz powinien być umieszczony w bloku <head> na samej stronie <link rel="canonical" href="https://site.com/catalog/shirt" />
Podobne strony
W raporcie duplikowanych stron zobaczysz również sekcję "podobne strony".
Podobne strony to strony, które różnią się tylko o kilka słów w porównaniu z innymi stronami na Twojej stronie.
Na przykład, jeśli wziąłeś treść jednej strony, zmieniłeś tylko kolor produktu lub nazwę miasta, a następnie zapisałeś ją pod innym URL, prawdopodobnie pokazałoby się to w tym raporcie podobnych stron.
Takie strony również prawdopodobnie wywołają kary za duplikowany content i powinny również być adresowane, postępując zgodnie z tymi samymi praktykami i metodami wymienionymi w sekcji "Jak wyeliminować duplikowane strony ze swojej strony?" powyżej.
Jak naprawić problem
Duplikowany content w ramach Twojej strony występuje, gdy wiele stron ma identyczną treść.
Te strony psują wysiłki optymalizacji Twojej strony, ponieważ wyszukiwarki są wrażliwe na duplikowany content, dodaje to również niepotrzebnie do budżetu crawlania, rozcieńcza ranking strony i stawia Cię w konkurencji ze sobą, ponieważ wyszukiwarki nie wiedzą, którą stronę wybrać.
Aby to naprawić, możesz:
- Usunąć niepotrzebne parametry, które tworzą dodatkowe URL prowadzące do tej samej strony.
- Jeśli nie ma wielu stron z problemem, możesz po prostu zabronić indeksowania duplikowanych URL lub niektórych sekcji kategorii.
- Użyć atrybutu rel=canonical, aby określić 'główną stronę' wszystkich duplikowanych stron. Robiąc to, ustaw najbardziej autorytatywną stronę jako kanoniczną.
Czytaj więcej tutaj o tym, jak wdrożyć te kroki: https://labrika.com/help/docs/pages_duplicates.