Jak skutecznie blokować strony przed indeksacją w SEO
Czym jest indeksacja?
Indeksacja to proces analizowania stron witryny (zwykle wykonywany przez wyszukiwarki) i po przeszukiwaniu dodawania ich do indeksów wyszukiwarek. Ten indeks (baza danych) jest następnie wykorzystywany do tworzenia wyników wyszukiwania, a także do rankingu stron w wynikach wyszukiwania (po dalszej analizie stron przez algorytmy pod kątem satysfakcji z intencji zapytania i skutecznego SEO). Indeksacja jest wykonywana przez crawlera/robota wyszukiwarki.
Dlaczego potrzebujemy możliwości wykluczania informacji z indeksów wyszukiwarek?
Jako zasadę ogólną, informacje, które nie powinny być wyświetlane w wynikach wyszukiwania, można zablokować przed indeksami wyszukiwarek za pomocą tagu „noindex” lub poprzez blokowanie przeszukiwania określonych sekcji/stron witryny w pliku robots.txt.
Strony zwykle blokowane przed wyszukiwarkami mają charakter techniczny, własnościowy i poufny oraz są uznawane za nieodpowiednie do umieszczenia w wynikach wyszukiwania.
Przykłady tego w witrynie handlowej mogą obejmować linki wskazujące na; konta użytkowników, koszyki zakupowe, porównania produktów, strony duplikowane, wyniki wyszukiwania w witrynie i tak dalej!
Te strony są cenne dla klientów i niezbędne dla funkcjonalności witryny, ale nie są przydatne dla indeksów wyszukiwarek.
Sposoby blokowania stron przed indeksacją przez wyszukiwarki
Istnieje wiele sposobów zapobiegania indeksacji stron:
-
Używanie pliku robots.txt.
Robots.txt to plik tekstowy, który mówi wyszukiwarkom, które strony mogą indeksować, a które nie.
Aby zablokować stronę przed indeksacją w robots.txt, musisz użyć dyrektywy Disallow.
Przykład pliku robots.txt, który pozwala na indeksację stron katalogu, jednocześnie zabraniając indeksacji koszyka:
# Treść pliku robots.txt, # który musi znajdować się w katalogu głównym witryny # włącz indeksację stron i plików zaczynających się od '/catalog' Allow: /catalog # zablokuj indeksację stron i plików zaczynających się od '/cart' Disallow: /cart
-
Używanie tagu <meta> robots z atrybutem noindex.
Aby zablokować stronę za pomocą tego atrybutu, musisz dodać następujące wiersze do sekcji
<head>strony:Aby zablokować całą stronę przed indeksacją, powinieneś umieścić następujący wiersz w bloku
<head>samej strony:<meta name="robots" content="noindex">
-
Dodawanie nofollow do linków, aby nie indeksowały strony, do której prowadzą.
Istnieją dwa sposoby, aby to zrobić:
-
Blokowanie crawlera przed podążaniem za linkiem na podstawie pojedynczego linku:
<a href="/page" rel="nofollow"> tekst linku </a>
Pamiętaj, że ta metoda będzie działać tylko wtedy, gdy każdy pojedynczy link do strony ma atrybut „nofollow”. Jeśli jeden link brakuje tego atrybutu, crawler wyszukiwarki podąży za nim, a strona nadal zostanie zaindeksowana.
-
Blokowanie crawlera przed podążaniem za dowolnym linkiem na stronie poprzez nadanie samej stronie atrybutu nofollow:
Dodając poniższy wiersz do bloku
<head>na stronie, crawler zostanie zablokowany przed podążaniem za stroną, a zatem wszelkie linki zawarte na stronie nie zostaną zaindeksowane.<meta name="robots" content="nofollow" />
-
-
Można również zablokować stronę przed przeszukiwaniem przez dowolną konkretną wyszukiwarkę w nagłówku strony HTML, na przykład:
Możesz umieścić ten wiersz w bloku
<head>na samej stronie; to zablokuje stronę przed indeksacją przez Google (ponieważ całkowicie zablokowałeś ich crawlera):<meta name="googlebot" content="noindex">
Możesz również wybrać „noindex” dla konkretnej strony, jednocześnie pozwalając Google na podążanie za linkami na wspomnianej stronie, a następnie indeksację stron, do których prowadzą linki ze strony „noindex”:
<meta name="googlebot" content="noindex, follow">
-
Strona kanoniczna.
Atrybut rel=canonical jest używany do wskazania wyszukiwarce, że strona jest stroną kanoniczną (najbardziej autorytatywną). To wskazuje crawlerowi, że jest to preferowana strona do indeksacji i jest najbardziej autorytatywnym przykładem tej treści na ich witrynie.
Określanie stron kanonicznych jest konieczne, aby uniknąć indeksacji stron o identycznej treści, co może następnie zaszkodzić rankingowi strony w SERP.
Będziesz używać tego atrybutu, gdy masz wiele stron o identycznej treści, ale z różnymi URL-ami dla różnych urządzeń:
https://example.com/news/https://m.example.com/news/https://amp.example.com/news/
Lub gdy dostępne są kilka opcji „sortowania” dla strony, które zmienią URL strony, ale pokażą tę samą treść:
https://example.com/catalog/https://example.com/catalog?sort=datehttps://example.com/catalog?sort=cost
Lub jeśli link określa różne rozmiary danego produktu w URL:
https://example.com/catalog/shirthttps://example.com/catalog/shirt?size=XLhttps://example.com/catalog/shirt38
Atrybut rel=canonical jest stosowany w następujący sposób:
<link rel=canonical href="https://example.com/catalog/shirt" />
Uwaga: powinieneś umieścić ten atrybut w bloku
<head>stronyMożliwe jest również wprowadzenie żądanej strony kanonicznej w nagłówku żądania HTTP.
Jednak bądź ostrożny, ponieważ bez użycia specjalnych wtyczek dla przeglądarki, nie będziesz w stanie stwierdzić, czy ten atrybut został prawidłowo ustawiony, ponieważ większość przeglądarek nie pokazuje nagłówków HTTP użytkownikom.
HTTP / 1.1 200 OK Link: <https://example.com/catalog/shirt>; rel=canonical
Możesz przeczytać więcej o stronach kanonicznych w dokumentacji Google.
-
Używanie nagłówka żądania HTTP „X-Robots-Tag” dla konkretnego URL:
HTTP / 1.1 200 OK X-Robots-Tag: google: noindex
Bądź ostrożny, ponieważ bez użycia specjalnych wtyczek dla przeglądarki, nie będziesz w stanie stwierdzić, czy ten atrybut został prawidłowo ustawiony, ponieważ większość przeglądarek nie pokazuje nagłówków HTTP użytkownikom.
Jak znaleźć strony, które zostały zablokowane przed indeksacją na mojej witrynie?
Możesz wyświetlić te informacje w sekcji „Audyt SEO” - „Strony zablokowane przed indeksacją” swojego panelu Labrika.
Na stronie raportu możesz filtrować wyniki, aby zobaczyć wszelkie strony docelowe, które zostały zablokowane przed indeksacją. Aby to zrobić, musisz kliknąć przycisk „krytyczny błąd”.
Zwykle, gdy crawler wyszukiwarki odwiedza Twoją witrynę, przeszuka wszystkie strony, które może znaleźć poprzez linki wewnętrzne, a następnie zaindeksuje je odpowiednio.
Celem tego raportu jest pokazanie wszelkich stron, które zostały zablokowane przed indeksacją. Są to zwykle strony, które nie mają słów kluczowych w top 50 wyników wyszukiwania i mogą być celowo zablokowane przed indeksacją przez wyszukiwarki przez Ciebie.
Raport Labrika „Strony zablokowane przed indeksacją”
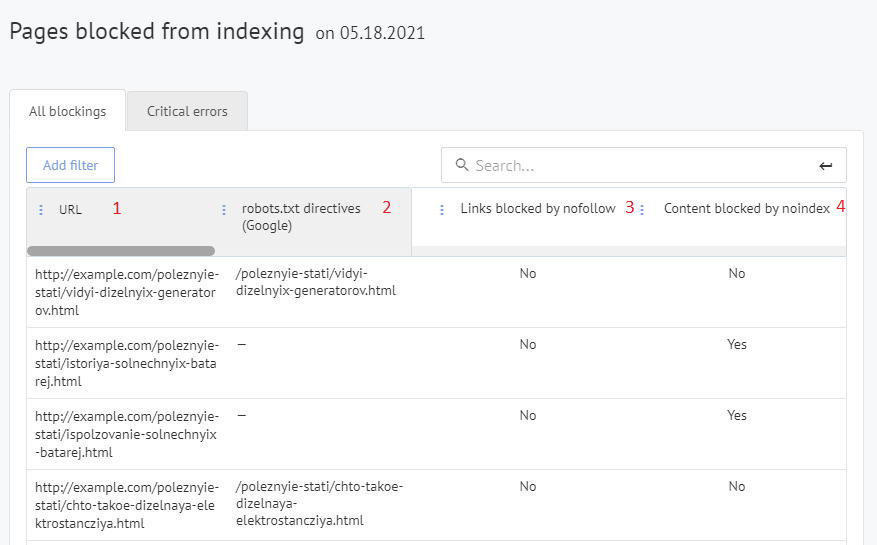
- URL wszelkich stron, które są obecnie zablokowane przed indeksacją.
- Dyrektywa w robots.txt, która blokuje indeksację dla tej strony (jeśli strona jest zablokowana przed indeksacją w Google tą metodą).
- Czy ta strona została zablokowana poprzez atrybut nofollow.
Jak przestać noindexować stronę, która znajduje się w tym raporcie?
W wielu nowoczesnych systemach zarządzania treścią (CMS) możesz zmienić plik robots.txt, rel=canonical, tag meta „robots”, atrybuty „noindex” i „nofollow”. Dlatego, aby ponownie uczynić stronę indeksowalną, która jest zawarta w tym raporcie, musiałbyś tylko usunąć atrybut/tag powodujący, że strona nie jest indeksowana. Istnieje wiele prostych wtyczek, które pozwalają to zrobić. Jeśli nie jesteś w stanie tego zmienić sam, byłoby to stosunkowo proste zadanie do outsourcingu do programisty.